AI绘画之输入文字生成图片
前言
最近都想着先把 Stable Diffusion Webui 的基础用法讲明白,让大家能够轻松的上手制作自己想要的图片。工作上也有点忙,每天回到家也是10点多了,近期每一篇文章发出都是在凌晨两三点。文章内容如果有晦涩难懂的地方,可以评论区告诉我,我会马上修改的。
下载模型
C 站 里有各路大佬训练出来并上传免费下载使用的模型,你也可以将自己训练的模型上传到这里。点击前面的链接进入C 站,找到你喜欢的模型并下载,注意要下载大模型,也就是大小要有1GB以上的模型,也可以直接筛选下载CHECKPOINT类型的模型。
下载完后,将模型放到 stable-diffusion-webui\models\Stable-diffusion 文件夹中,然后打开 Stable Diffusion Webui 页面,在页面左上角有一个下拉框,点击下拉框找到你刚刚的模型,如果找不到,可以点击下拉框右边的刷新图标,点击它即可刷新出你刚刚放置进去的模型,如果刷新不出来,请重新运行启动项目。
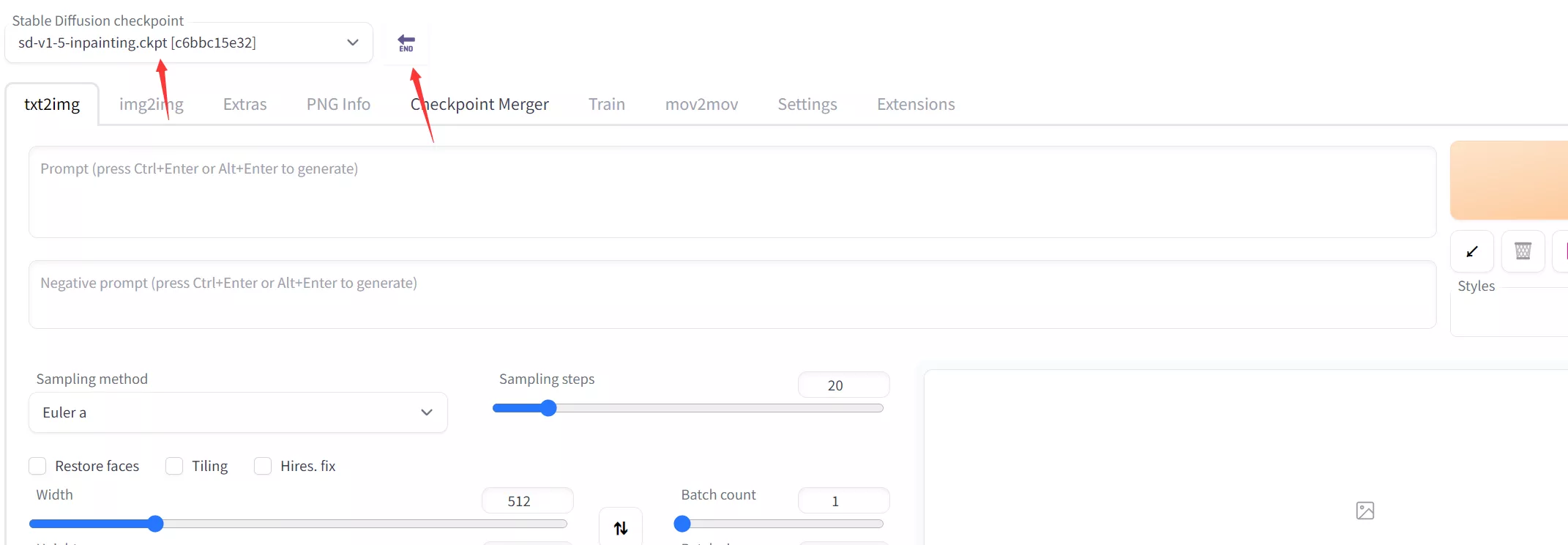
文字提示词
当选择完模型之后,就可以到文字提示词输入框中输入你想要的提示词了,如下图: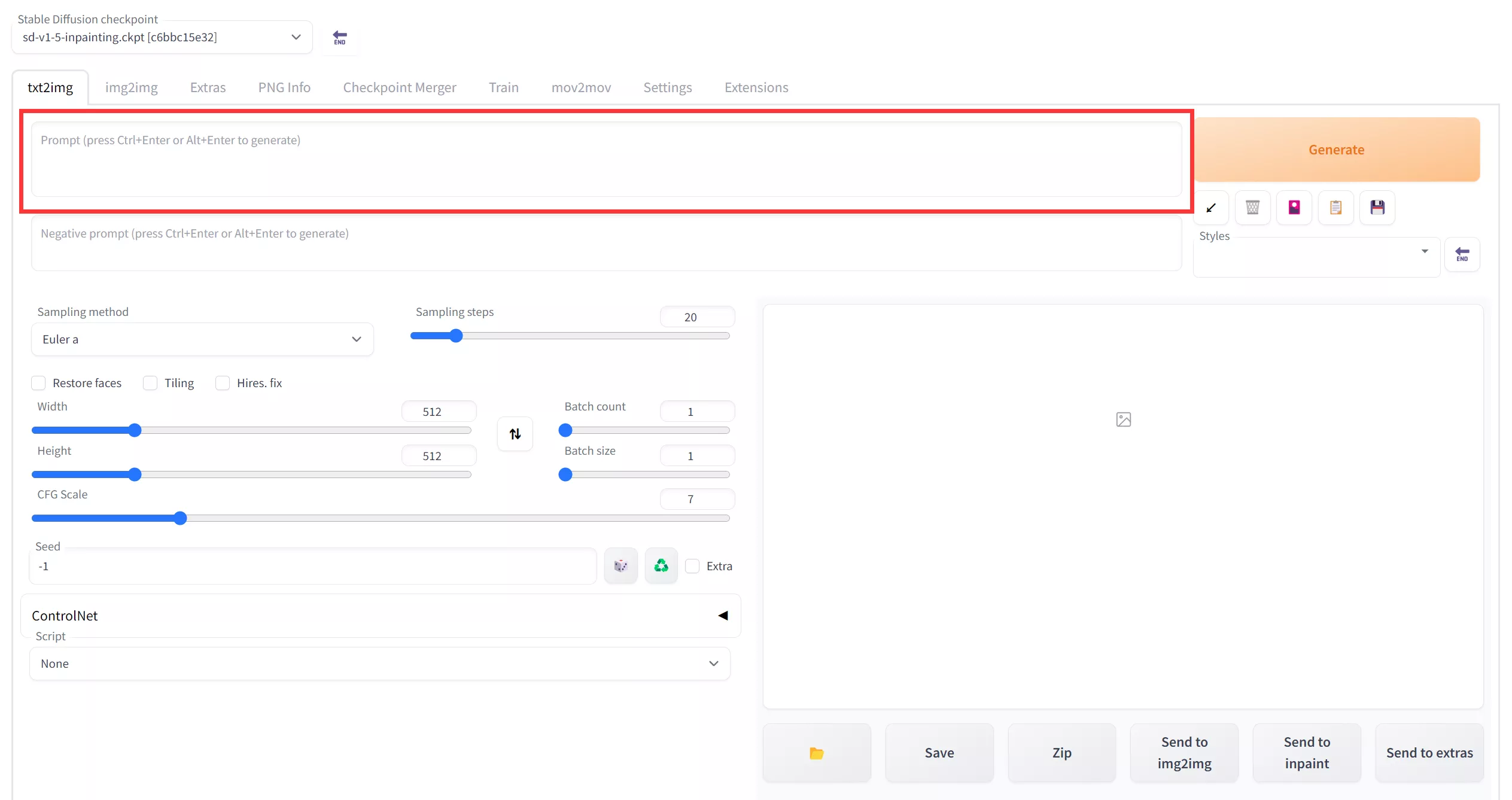
因为不同的模型,输入相同的提示词都会生成不同的图片,因为他们的风格不相同,所以这个具体效果要在C站上查看具体的模型的相关提示词了,一般在模型的封面处,点击它的图片,进入的页面中右边就是该图片的提示词,如下图: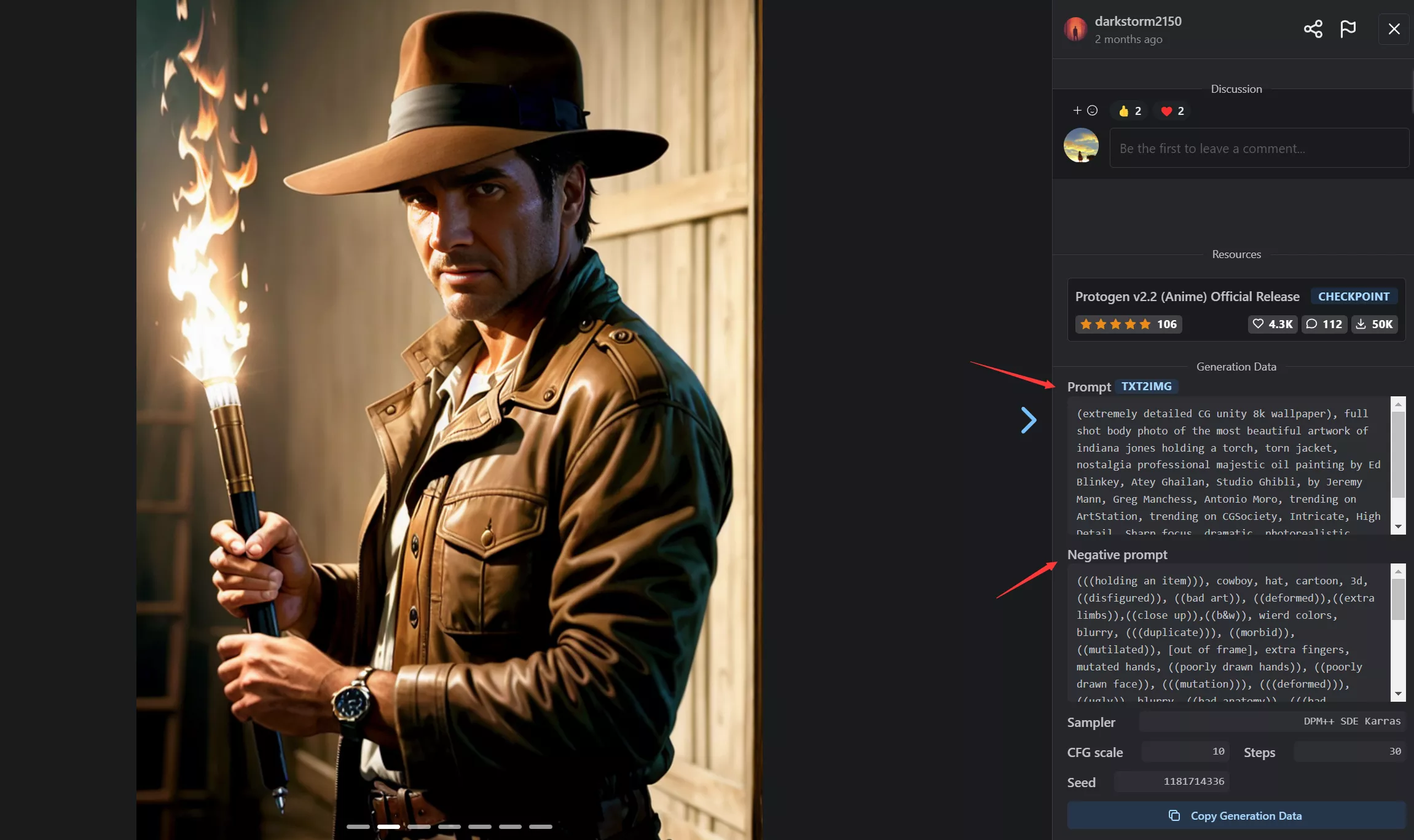
Prompt搜索
Lexica 是一个可以搜索图片的网站,并且搜索出来的图片还会提供对应的prompt给你,还能在图片上添加或者删减prompt来进行二次创作,如下图: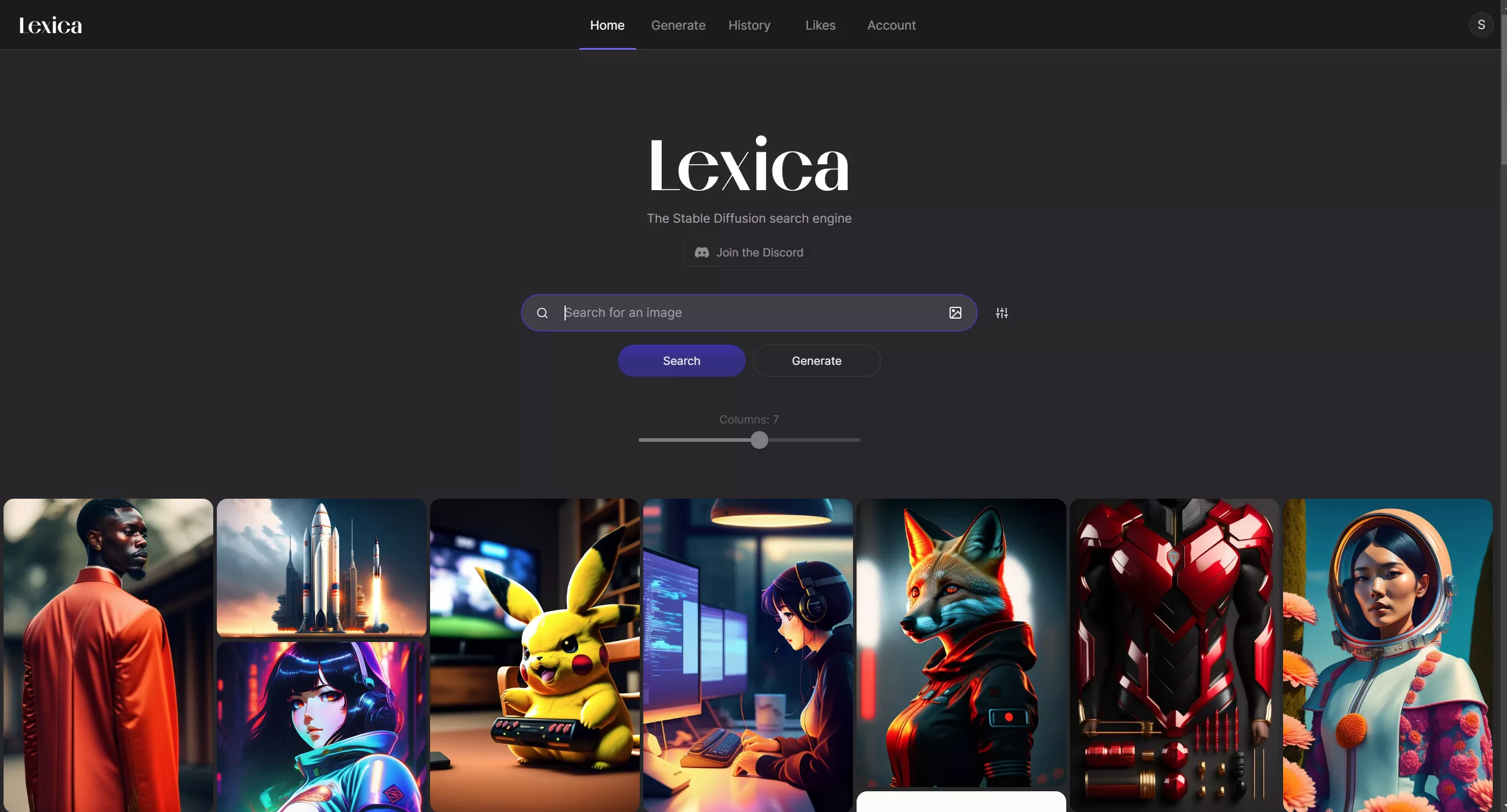
随便点击一张图片,在弹出的窗口中可以看到 copy prompt按钮 和 open in editor按钮,他们分别是复制和编辑,如下图: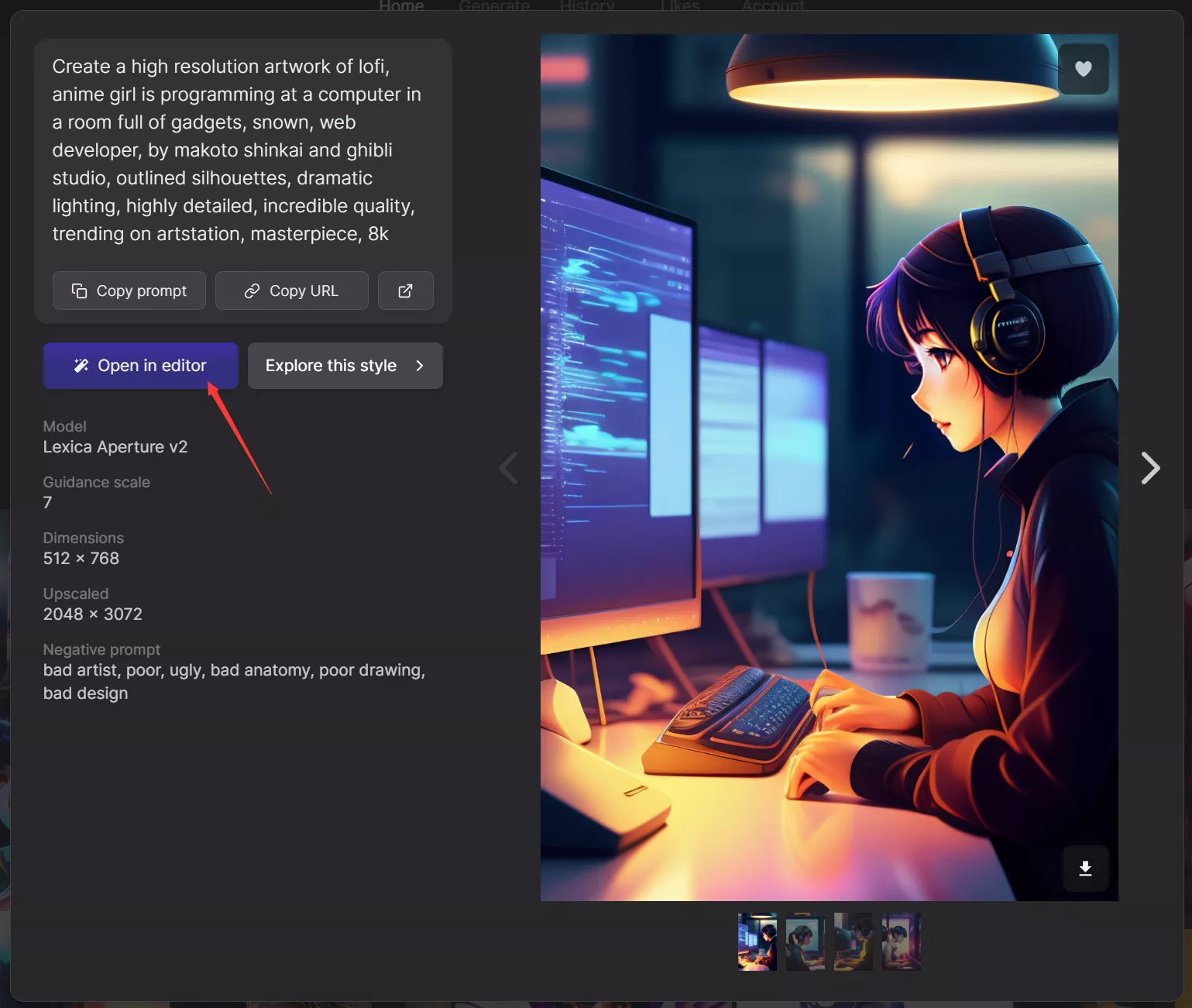
当我们点击 open in editor按钮 后,将会进入如下页面: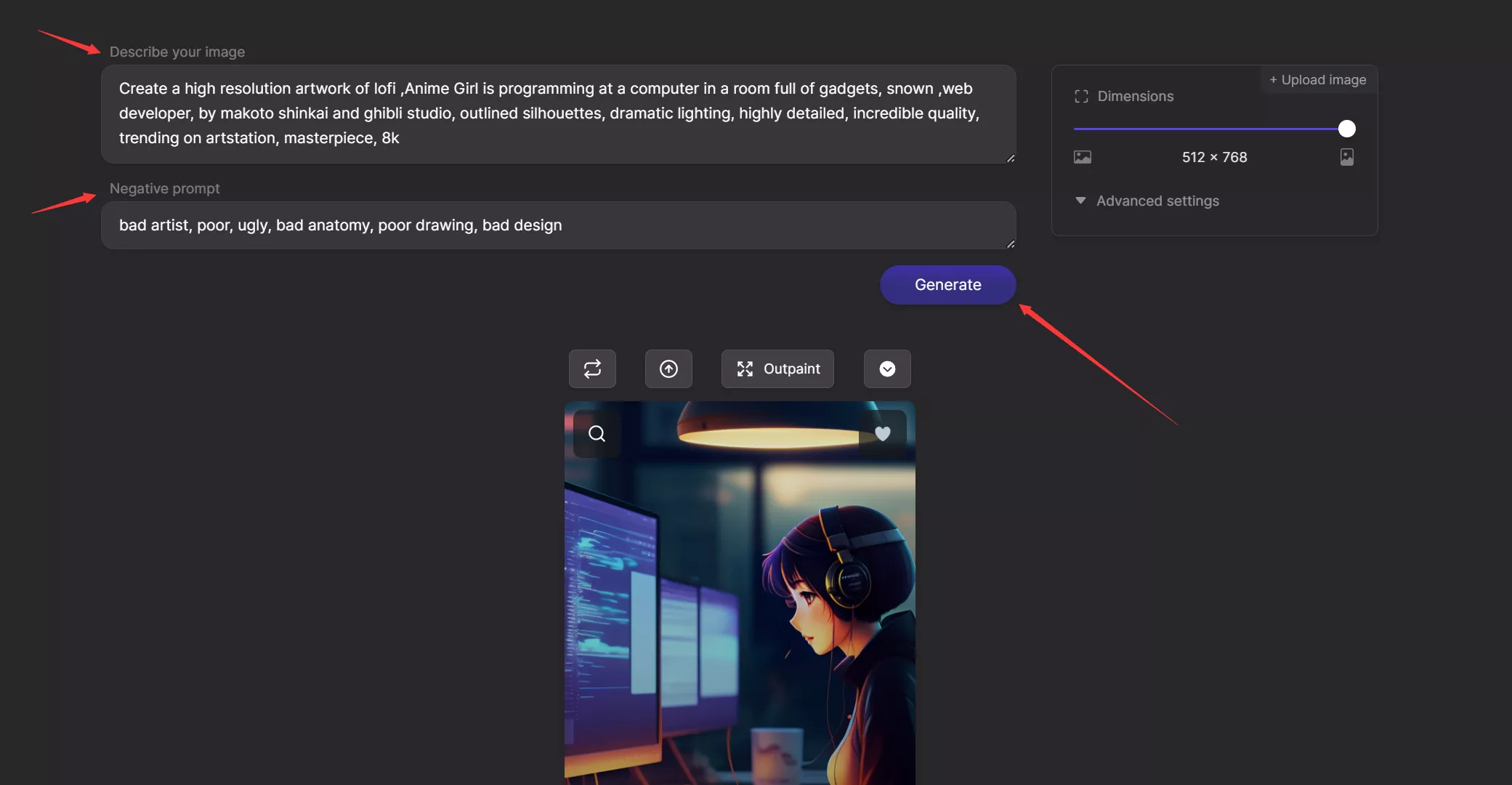
在页面中,最上面的第一栏输入框对应的就是prompt提示词,再往下的第二个输入框对应的就是Negative prompt提示词,我们可以在这里进行自己想要的修改,修改完后,我们可以点击右下角的 Generate按钮 进行生成,等待一会儿就会有新生成的图片显示出来了。
 微信
微信- 支付宝











